|
Traditional and Object-Centric Process Mining |
Scroll Previous Topic Top Next Topic More |
In many processes, there are different possibilities to choose one Case ID for the event log. For example, if you place an order with an online retailer this order can contain multiple items. These items can be shipped in one or more packages. In addition, through clever pooling, a package might not only contain items for exactly one order, but be used for several orders at the same time, like when multiple employees of a company buy things from the same supplier and they are all shipped in the same package. Traditional process mining requires that for the entire process, all events are related to exactly one type of Case ID.
This often creates a dilemma of deciding which is the correct CaseID - the order to which all events for individual items or packages are then related, or the package, to which all events of the orders and items are then assigned?
Both choices have disadvantages. In the order-Case ID, for example, some loops can pop up for the item events or for the package events, if there are multiple. For a package Case ID, on the other hand, there would be no loops, but duplicates of the events - such as placing order (for order 1 and order 2), or picking (order 1 items and order 2 items), etc since for each package the events of the order have to be shown individually. These two effects are called:
•Convergence - when one event is replicated across different cases, possibly leading to unintentional duplication. This replication of events can cause misleading diagnostics.
•Divergence - when there may be multiple instances of the same activity within a single case. Events on a lower entity level may become indistinguishable and seemingly related. For example, the pick item and pack item events happen only once per item and in a fixed sequence (e.g., you pick the item, then pack it), but within a flattened sales order event log these events may appear to happen many times and in a seemingly random order for an individual case.
Apart from these two effects, traditional mining has further disadvantages as
1.Data extraction and transformation is painful as relations between many objects need to be reconstructed meticulously.
2.Interactions between single objects are not captured correctly.
3.Multiple process dimensionality in reality is squeezed into 2D ("flattened") event logs and models.
Object-centric process mining addresses these limitations of traditional process mining by not defining events as being related to a single case. With this approach, events are no longer related to some previously defined Case ID but to the object which caused the event. Thus, in object-centric process mining a Case ID is no longer of one type, but has several types. Let's take the example from above - events caused by packages are related to the package ID. Events caused by the items belong to the items and the sales orders' events are connected by the sales order's ID. To relate the objects among each other links are established, thus a inter-object analysis can be carried out easily.
This technique brings several advantages, including not only simplified analysis of processes, but also shortened project cycles due to more realistic event log creation:
•Far less process variants lead to better readability of the ProcessAnalyzer.
•Better visibility and analysis of sub or side processes.
•Processes in which objects run in parallel can be better analyzed, since parallel events no longer generate a high number of variants due to flattening.
•Easier detection of insights due to less inter-object event mix-up (convergence & divergence)
•Facilitated event log creation as object IDs are normally directly connected to their events, while the traditional Case ID needed careful data modeling and transformation.
The main advantages become very clear when comparing the same process shown in the traditional vs the object-centric approach:
Object-Centric ProcessAnalyzer |
Traditional ProcessAnalyzer |
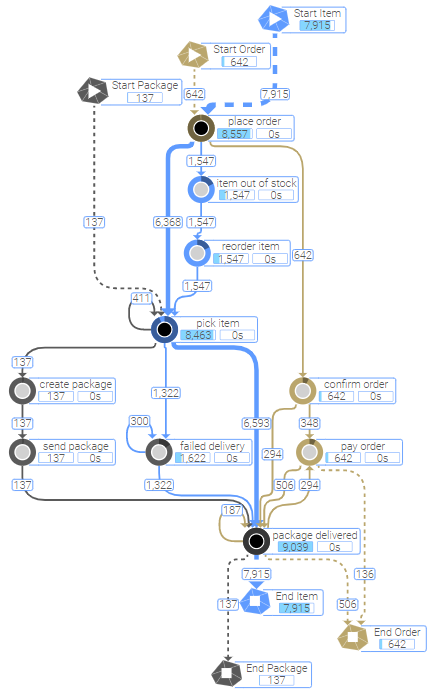 |
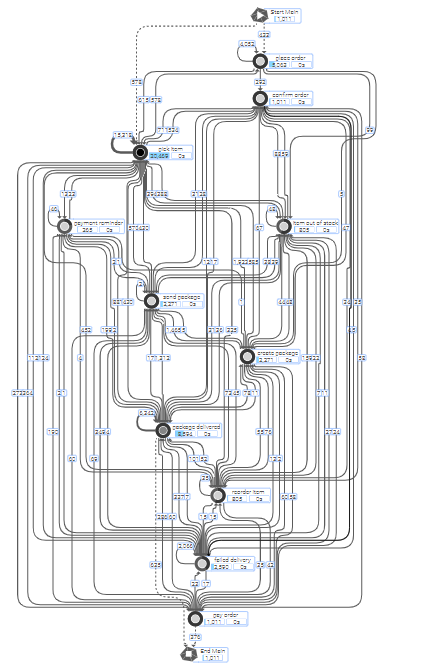 |
MEHRWERK ProcessMining includes the object-centric approach openly available for our customers as of the December 2022 Release. Of course, the traditional approach is still available and recommended in some use cases. How to activate one or the other approach is closely described in the Data Engineer Guide. Configurations regarding the OCPM or the traditional ProcessAnalyzer-functionality are given in the Business Analyst Guide. Last but not least, information and instruction for the use of the OCPM or traditional analytic dashboard are given in the Business User Guide.