|
Traditionelles und Object-Centric Process Mining |
Scroll Previous Topic Top Next Topic More |
Bei vielen Prozessen gibt es verschiedene Möglichkeiten, eine Fall-ID für das Event Log zu wählen. Wenn Sie zum Beispiel eine Bestellung bei einem Online-Händler aufgeben, kann diese Bestellung mehrere Artikel enthalten. Diese Artikel können in einem oder mehreren Paketen verschickt werden. Darüber hinaus kann ein Paket durch geschicktes Pooling nicht nur Artikel für genau eine Bestellung enthalten, sondern auch für mehrere Bestellungen gleichzeitig verwendet werden, z. B. wenn mehrere Mitarbeiter eines Unternehmens beim selben Lieferanten einkaufen und alle Artikel im selben Paket versandt werden. Traditionelles Process Mining setzt voraus, dass für den gesamten Prozess alle Events mit genau einem Typ von Case ID verbunden sind.
Dies führt oft zu dem Dilemma zu entscheiden, welches die korrekte CaseID ist - die Bestellung, auf die dann alle Events für einzelne Artikel oder Pakete bezogen werden, oder das Paket, dem dann alle Events der Bestellungen und Artikel zugeordnet werden?
Beide Möglichkeiten haben Nachteile. Bei der Bestellung-Case-ID können beispielsweise einige Schleifen für die Ereignisse "Artikel" oder "Paket" auftreten, wenn es mehrere gibt. Bei einer Paket-Fall-ID hingegen gäbe es keine Schleifen, sondern Duplikate der Events - wie z. B. Bestellung (für Bestellung 1 und Bestellung 2) oder Kommissionierung (Bestellung 1 und Bestellung 2) usw., da für jedes Paket die Events der Bestellung einzeln angezeigt werden müssen. Diese beiden Effekte werden als:
•Konvergenz - wenn ein Event in verschiedenen Fällen wiederholt wird, was zu unbeabsichtigten Duplikationen führen kann. Diese Replikation von Events kann zu irreführenden Diagnosen führen.
•Divergenz - wenn es mehrere Instanzen derselben Aktivität innerhalb eines einzigen Falles geben kann. Ereignisse auf einer niedrigeren Entitätsebene können ununterscheidbar werden und scheinbar zusammenhängen. Beispielsweise finden die Ereignisse "Artikel kommissionieren" und "Artikel verpacken" nur einmal pro Artikel und in einer festen Reihenfolge statt (z. B. Sie kommissionieren den Artikel, dann verpacken Sie ihn), aber in einem reduzierten Event Log eines Kundenauftrags können diese Ereignisse viele Male und in einer scheinbar zufälligen Reihenfolge für einen einzelnen Fall vorkommen.
Abgesehen von diesen beiden Effekten hat der traditionelle Bergbau noch weitere Nachteile, wie zum Beispiel:
1.Die Datenextraktion und -umwandlung ist mühsam, da die Beziehungen zwischen vielen Objekten akribisch rekonstruiert werden müssen.
2.Interaktionen zwischen einzelnen Objekten werden nicht korrekt erfasst.
3.Die Mehrfachdimensionalität von Prozessen in der Realität wird in 2D-Event Logs und Modelle gepresst ("abgeflacht").
Das Object-Centric Process Mining geht diese Einschränkungen des traditionellen Process Mining an, indem es Ereignisse nicht als auf einen einzelnen Fall bezogen definiert. Bei diesem Ansatz sind Ereignisse nicht mehr mit einer zuvor definierten Case ID verbunden, sondern mit dem Objekt, das das Ereignis verursacht hat. Beim Object-Centric Process Mining ist eine Case ID also nicht mehr nur von einem Typ, sondern hat mehrere Typen. Nehmen wir das obige Beispiel: Ereignisse, die durch Pakete verursacht werden, sind mit der Paket-ID verbunden. Ereignisse, die durch Artikel verursacht werden, gehören zu den Artikeln, und die Ereignisse der Kundenaufträge sind durch die ID des Kundenauftrags verbunden. Um die Objekte untereinander in Beziehung zu setzen, werden Verknüpfungen hergestellt, so dass eine objektübergreifende Analyse leicht durchgeführt werden kann.
Diese Technik bringt mehrere Vorteile mit sich, darunter nicht nur eine vereinfachte Analyse von Prozessen, sondern auch verkürzte Projektzyklen aufgrund einer realistischeren Erstellung von Event Logs:
•Deutlich weniger Prozessvarianten führen zu einer besseren Lesbarkeit des ProcessAnalyzers.
•Bessere Sichtbarkeit und Analyse von Unter- oder Nebenprozessen.
•Prozesse, in denen Objekte parallel ablaufen, können besser analysiert werden, da parallele Events aufgrund der Verflachung nicht mehr eine hohe Anzahl von Varianten erzeugen.
•Leichtere Erkennung von Erkenntnissen durch weniger Vermischung von Events zwischen Objekten (Konvergenz & Divergenz)
•Erleichterte Erstellung von Event Logs, da Objekt-IDs in der Regel direkt mit ihren Events verbunden sind, während die herkömmliche Case-ID eine sorgfältige Datenmodellierung und -umwandlung erforderte.
Die Hauptvorteile werden sehr deutlich, wenn man den gleichen Prozess im traditionellen und im objektzentrierten Ansatz vergleicht:
Object-Centric ProcessAnalyzer |
Traditional ProcessAnalyzer |
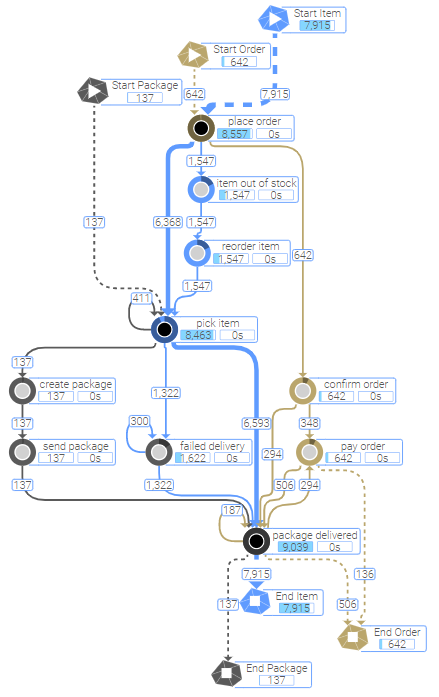 |
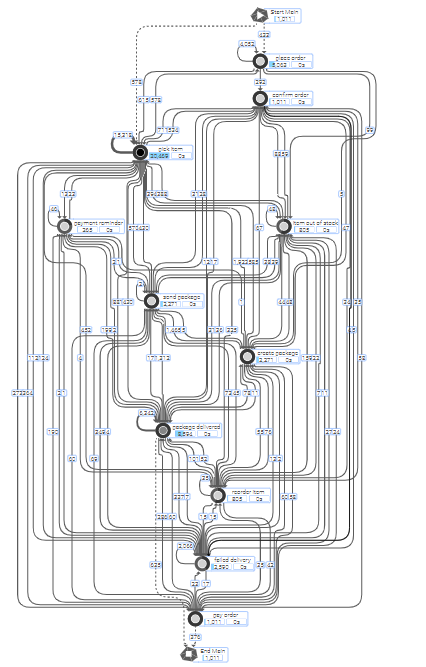 |
MEHRWERK mpmX analytics beinhaltet den objektzentrierten Ansatz, der ab dem Release Dezember 2022 für unsere Kunden offen zugänglich ist. Natürlich ist der traditionelle Ansatz weiterhin verfügbar und wird in einigen Anwendungsfällen empfohlen. Wie man den einen oder anderen Ansatz aktiviert, wird im Data Engineer Guide genau beschrieben . Konfigurationen bezüglich der OCPM- oder der traditionellen ProcessAnalyzer-Funktionalität finden Sie im Business Analyst Guide. Nicht zuletzt finden Sie im Business User Guide Informationen und Anleitungen zur Verwendung des OCPM oder des traditionellen analytischen Dashboards.